이전 글
하둡 분산 파일 시스템(Hadoop Distributed File System, HDFS) 이란?
이전 글 https://nanocoding.tistory.com/entry/%ED%95%98%EB%91%A1Hadoop%EC%9D%B4%EB%9E%80-HDFS-MapReduce-EcoSystem-YARN-%ED%95%9C%EB%B2%88%EC%97%90-%EB%B3%B4%EA%B8%B0 하둡(Hadoop)이란? - HDFS, MapReduce, EcoSystem, YARN 한번에 보기 하둡은 빅
nanocoding.tistory.com
맵리듀스(MapReduce)
맵리듀스란 HDFS에 분산 저장된 데이터에 스트리밍 접근을 요청하며 빠르게 분산처리하도록 고안된
프로그래밍 모델입니다. 또 이를 지원하는 시스템입니다.
- 대규모 분산 컴퓨팅 혹은 단일 컴퓨팅 환경에서 개발자가 대량의 데이터를 병렬로 분석할 수 있음
- 개발자는 맵리듀스 알고리즘에 맞게 분석 프로그램을 개발하고, 데이터의 입출력과 병렬처리 등의 기반 작업은 프레임워크가 알아서 처리해 줌
하둡은 분산처리가 가능한 시스템과 분산되어 저장된 데이터를 병렬로 처리가능하게 하는
맵리듀스 프레임워크를 결합한 단어라고 할 수 있습니다.
즉, HDFS는 대용량 파일을 지리적으로 분산되어 있는 수많은 서버에 저장하는 솔루션이고,
MapReduce는 분산되어 저장된 대용량 데이터를 병렬로 처리하는 솔루션입니다

1. MapReduce Architecture
1.1 동적 관점
① 태스크(Task)
> 맵퍼나 리듀서가 수행하는 단위 작업 (Map Task, Reduce Task)
> 맵 혹은 리듀스를 수해하기 위한 정보를 가지고 있음
② 맵퍼(Mapper)
> 구성: 맵(Map), 컴바인(Combine), 파티션(Partition)
> 맵 동작: 인풋 데이터를 가공하여 사용자가 원하는 정보를 Key/Value 쌍으로 변환
③ 리듀서(Reducer)
> 구성: 셔플(Shuffle), 정렬(Sort), 리듀스(Reduce)
> 리듀스 동작: 가공된 Key/Value를 Key를 기준으로 각 리듀서로 분배,
사용자가 정의한 방법으로 각 Key와 관련된 정보를 추출
1.2 매핑 프로세스
입력 파일
- HDFS에 있는 입력 파일을 분할하여 FileSplit을 생성
- FileSplit 하나당 Map Task를 하나씩 생성
맵(Map)
- 데이터를 읽어와서 KV페어 (Key-Value pair)를 생성
컴바인(Combine)
- KV리스트 (Key-Value list)에 대한 전처리를 수행
- 맵의 결과를 리듀서에게 보내기 전에 데이터를 최소화
- 리듀스와 동일한 함수를 사용
파티션(Partition)
- Key를 기준으로 디스크에 분할 저장 (해시(Hash) 파티셔닝 사용)
- 각 파티션은 키를 기준으로 정렬이 됨
- HDFS가 아닌 맵퍼의 Local File System에 저장
- 분할된 각 파일은 각각 다른 리듀스 태스크(Reduce Task)에 전달됨
1.3 리듀싱 프로세스
셔플(Shuffle)
- 여러 맵퍼에 있는 결과 파일을 각 리듀서에 할당
- 리듀서에 할당된 결과 파일을 리듀서의 로컬 파일 시스템으로 복사
정렬(Sort)
- 병합 정렬(Merge sort)을 이용하여 Mapper 결과 파일을 정렬 및 병합
- Key로 정렬된 하나의 커다란 파일이 생성됨
리듀스(Reduce)
- 정렬 단계에서 생성된 파일을 처음부터 순차적으로 읽으면서 리듀스 함수를 수행
1.4 노드 관점
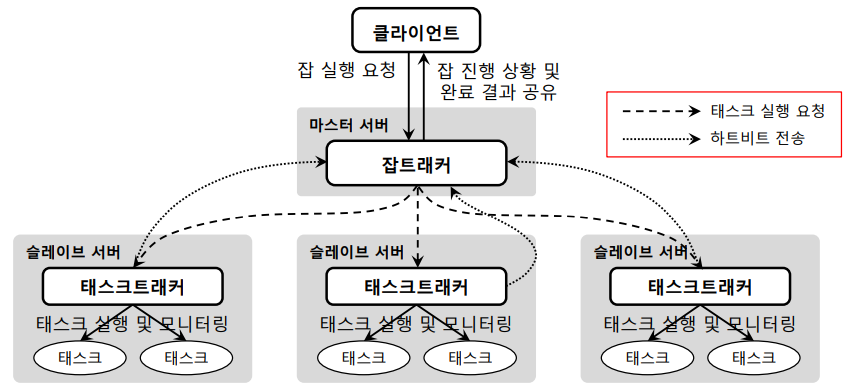
① 클라이언트(Client)
② 잡트래커(JobTracker)
③ 태스크트래커(TaskTracker)
노드 관점에서는 클라이언트, 잡트래커, 태스크트래커로 구성되어 있음을 확인할 수 있습니다.
1.5 Job Client의 역할
- 입력 데이터의 분할 방침을 결정
- 처리 대상 입력 데이터를 어떻게 분할하여 병렬 처리할지 결정
- JobTracker에게 MapReduce 잡을 의뢰
- MapReduce 잡을 실행하기 위한 애플리케이션을 HDFS에 저장
- JobTracker로부터 진행 상태를 수신
- 사용자 단위로 MapReduce 잡을 관리
- 잡의 우선순위를 변경하거나 잡을 강제 종료
1.6 JobTracker의 역할
- 잡 관리
- Map 태스크 할당 제어
- Map 처리 결과 파악
- JobClient에게 잡 진행 통지
- 리소스 관리
- TaskTracker에게 Map이나 Reduce 처리 할당
- 처리의 주기적 실행
- 이상 발생 시 처리를 재할당
- 처리 실패 빈도가 높은 TaskTracker 블랙리스트 생성
- TaskTracker 동작 여부 확인
- TaskTracker 추가 및 제외
- 잡 실행 이력 관리
1.7 TaskTracker의 역할
- Child 프로세스 생성과 처리 실행
- Child 프로세스: Map이나 Reduce 작업을 동작시키는 자바 프로세스
- Child 프로세스에게 jar파일이나 필요한 데이터를 전달
- Child 프로세스 상태 확인
- JobTracker로부터 처리 중지 지시가 오면, 처리 중지를 통지
- Map 처리 수와 Reduce 처리 수를 파악
- JobTracker에게 주기적으로 하트비트 전송
- Map 또는 Reduce 동시 실행 가능한 슬롯 수 포함 (현재 빈 슬롯 수도)
2 MapReduce Version
하둡 1.0의 문제점은 관계형 데이터베이스 분석 시스템에 익숙한 많은 분석가들과 사용자들을
하둡으로 끌어들이는데 실패하는 원인이 되었습니다.
이러한 문제점을 해결하기 위해 하둡 2.0에서는 맵리듀스를 버리고 얀(Yet Another Resource Negotiator, YARN)을
채택하여 확장성과 데이터 처리 속도를 개선시켰습니다.
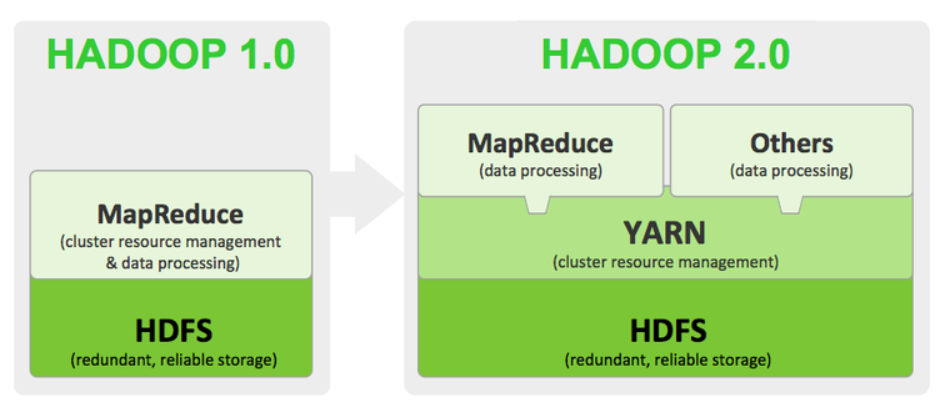
위 그림을 통해 버전의 차이를 확인할 수 있습니다.
하둡 1.0에서는 맵리듀스가 cluster resource management와 data processing을 처리하지만,
하둡 2.0에서는 맵리듀스가 data processing만을 처리하게 됩니다.
MapReduce와 HDFS의 관계
데이터 분할
- Hadoop에서는 데이터를 HDFS에 저장
- MapReduce가 잡 처리 시 HDFS에서 데이터를 읽고, 처리 결과를 HDFS에 저장
- 입력 데이터를 어떻게 분할하고 처리할지는 JobClient가 결정
- 하나의 Map Task는 하나의 스플릿에서 레코드를 읽어 처리
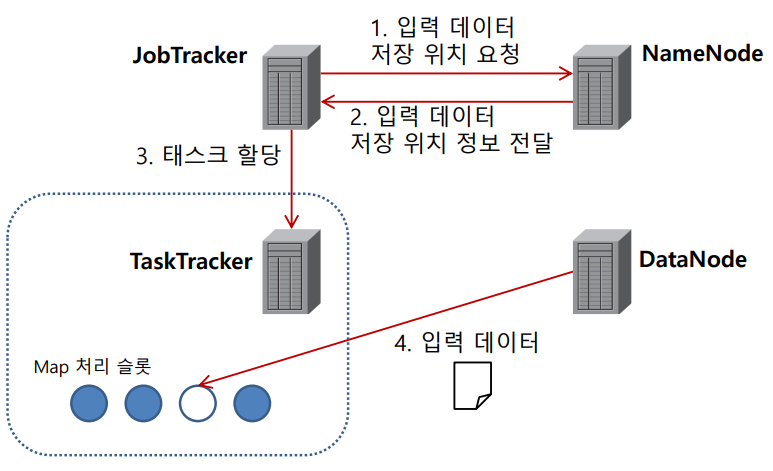
데이터 지역성
- 가능한 한, 데이터를 동작하고 있는 처리시스템에 옮기는 것이 아닌, 처리 프로그램을 데이터가 있는 곳으로 이동
- 노드 간 데이터 전송량을 줄이고, 대량의 데이터를 처리하더라도 최대한 오버헤드가 발생하지 않도록 함
- JobTracker는 NameNode와 소통해 가면서 Task를 할당

'Big Data > Hadoop' 카테고리의 다른 글
| 얀(Yet Another Resource Negotiator, YARN)이란? - 하둡 맵리듀스와 얀 (0) | 2023.08.21 |
|---|---|
| 하둡 에코시스템(Hadoop EcoSystem) - 하둡 프로젝트와 생태계 (0) | 2023.08.21 |
| 하둡 분산 파일 시스템(Hadoop Distributed File System, HDFS) 이란? (0) | 2023.08.21 |
| 하둡(Hadoop) 이란? - 빅데이터와 하둡 (0) | 2023.02.12 |




댓글