에어플로우(Airflow)
1. Airflow
에어플로우란 데이터 파이프라인 관리를 위한 오픈소스 플랫폼으로, 워크플로우 관리를 위한 툴입니다.
에어플로우는 초기 airbnb에서 기업의 점차 복잡해지는 워크플로우를 관리하기 위한 해결책으로서 개발되었습니다.
| 데이터 파이프라인(Data Pipeline): 데이터가 수집, 처리, 저장되는 즉, 데이터의 이동과 처리의 전체 프로세스 ** 데이터 파이프라인은 데이터 수집, 처리, 저장 등을 포함하는 넓은 범위의 개념 워크플로우(Workflow): 일련의 작업의 흐름 및 특정 작업을 완수하기 위한 일련의 태스크 또는 그들 간의 관계 예) ELT(Extract→Loading→Transformation), ETL(Extract→Transformation→Loading) ** 워크플로우는 데이터 파이프라인 내의 특정 부분을 구체적으로 정의하고 조직화하는 데 사용 |
1.1 특징
- Python3에서 프로그래밍 방식으로 파이프라인을 설계
- 예약 및 모니터링이 가능하며, 웹 UI를 제공
- Airflow는 하나 이상의 서버로 구성된 클러스터이고, Workers와 Scheduler로 구성되며, Scheduler는 작업을 여러 Workers에게 분산시킴
- DAG와 스케줄링 정보는 기본적으로 DB에 저장되지만, 실제 운영환경에서는 MySQL 또는 PostgreSQL을 사용하는 것이 좋음(성능, 기능상의 문제)
| 방향 비순환 그래프(Directed Acyclic Graph , DAG): Airflow에서 workflow를 구성하고 관리하는 핵심 개념으로, ETL 작업을 포함하여 다양한 데이터 처리 및 workflow를 DAG를 통해 정의하고 관리함 |
1.2 구성

Airflow는 5개의 컴포넌트로 구성되며, 각 구성 요소는 Airflow의 기능과 운영을 지원하는데 중요한 역할을 수행합니다.
① Webserver
: 로그를 보여주거나 스케줄러에 의해 생성된 DAG 목록, task 상태 등을 시각화
UI를 제공하며, DAG의 스케줄링, 실행 상태 확인, 워크플로우 모니터링 등을 웹 브라우저를 통해 관리할 수 있음
** python flask
② Scheduler
: 할당된 worker들을 스케줄링하고, 스케줄링된 workflow들의 triggering과 실행을 위해 executor에게 task를 제공
** Cron job의 문법을 그대로 사용
③ Executor
: 실행중인 task를 handling하며, default 설치 시에는 스케줄러에 있는 모든 것들을 다 실행시키지만,
production 수준에서의 executor는 worker에게 task를 push함
쉽게 말해, task의 실행 방식을 결정하며, 다양한 Executor(실행자)가 있음
** Local Executor, Celery Executor, Kubernetes Executor 등이 있음
④ Worker
: 실제 task를 실행하는 프로세스로, executor에 의해 할당된 task를 처리
** Worker는 CPU의 숫자만큼 정해짐
⑤ DataBase
: DAG, task 등의 metadata(Airflow의 상태, 작업 로그, 스케줄 정보 등)을 저장하고 관리
Airflow는 이 데이터베이스를 사용하여 workflow의 상태를 추적하고, 재시작 시에 필요한 정보를 유지
** 기본적으로 Sqlite
1.2.1 Queue(큐)
어떠한 설명에서는 Queue가 별도로 언급되기도 하기 때문에, 확실하게 짚고 넘어가겠습니다.
Queue는 task를 임시 저장하고, worker에게 전달하는 역할을 수행합니다.
특히, Celery Executor를 사용하는 경우, Redis나 RabbitMQ와 같은 메시지 브로커가 Queue의 역할을 수행합니다.
Queue는 멀티 노드 구성인 경우에만 사용되는데요.
Woker의 수 보다 데이터 파이프라인의 수가 많아질 경우, Worker는 Queue에 저장된 데이터 파이프라인 태스크를
순서대로 수행하며, 이 경우에는 Executor가 달라집니다.

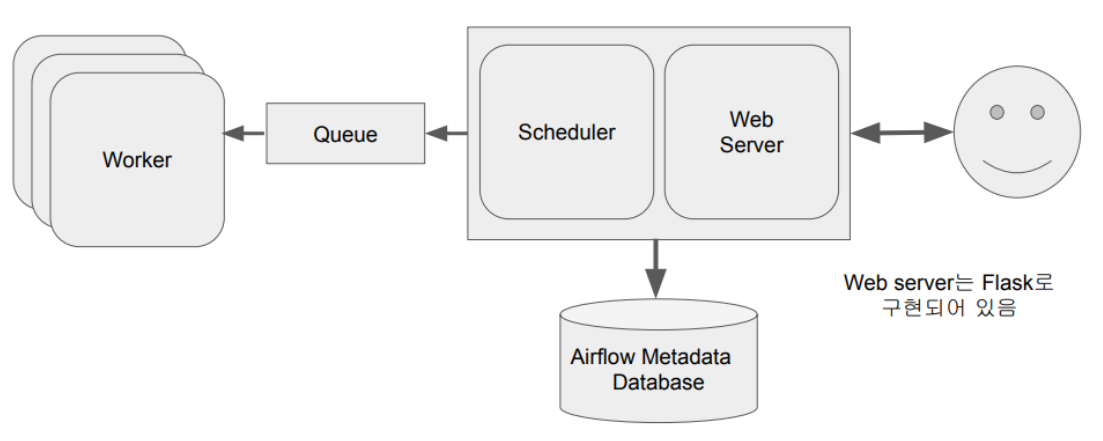
위 그림처럼, 서버가 여러 대 일때 메인 노드에서 Worker들은 분리됩니다.
이후, 스케줄러에 의 Queue로 DAG가 저장되고, Worker들은 Queue에 저장된 DAG를 보고 작업을 수행합니다.
1.3 동작 원리

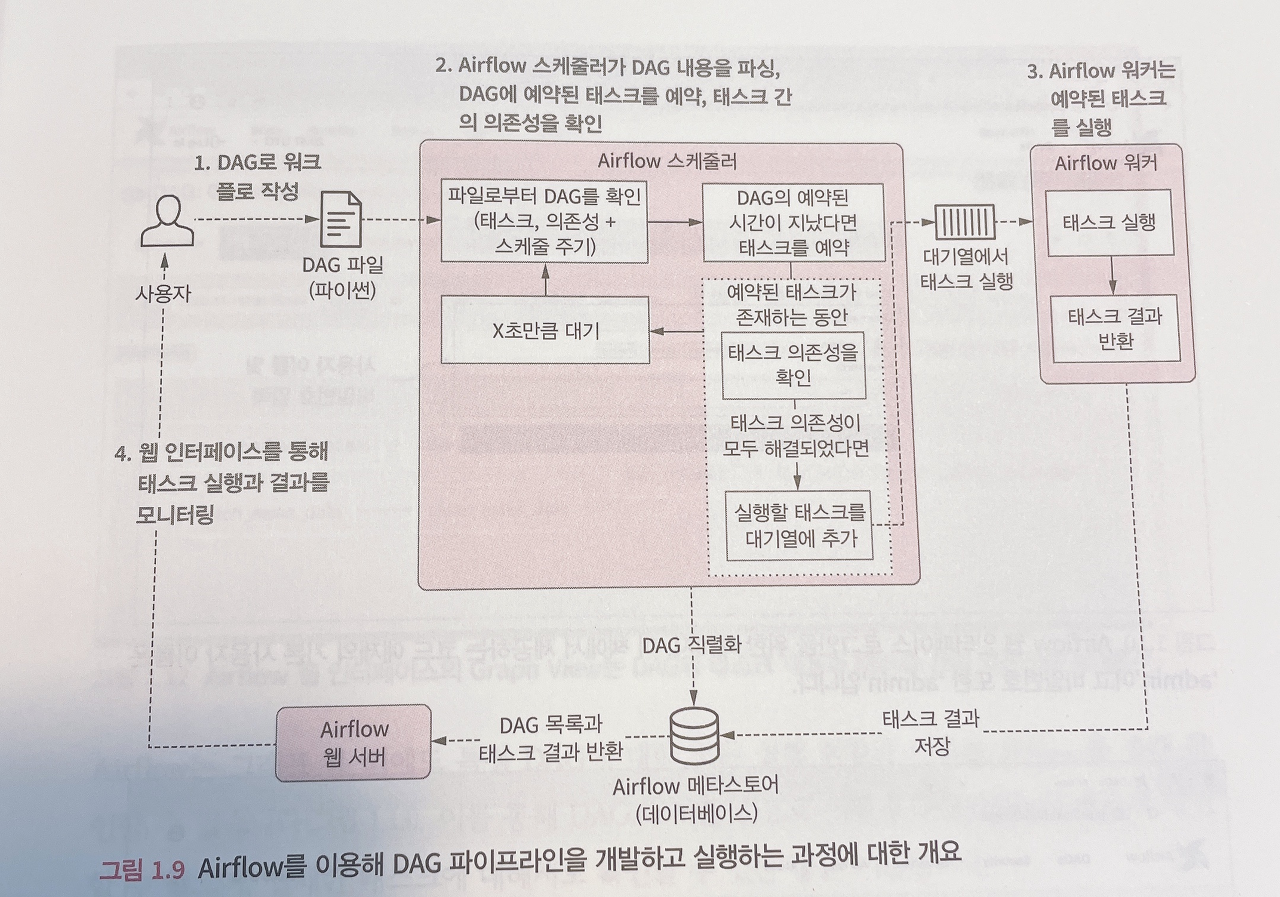
⑴ 유저가 새로운 Dag를 작성 → Dags Foolder 안에 .py 파일 배치
⑵ Web Server와 Scheuler가 파싱하여 읽어옴
⑶ Scheduler가 Metastore를 통해 DagRun 오브젝터를 생성함
- DagRun은 사용자가 작성한 Dag의 인스턴스
- DagRun Status : Running
⑷ 스케줄러는 Task Instance Object를 스케줄링함
- Dag Run object의 인스턴스
⑸ 트리거가 상황이 맞으면 Scheduler가 Task Instance를 Executor로 보냄
⑹ Exeutor는 Task Instance를 실행시킴
⑺ 완료 후 → MetaStore에 완료했다고 보고함
- 완료된 Task Instance는 Dag Run에 업데이트됨
- Scheduler는 Dag 실행이 완료되었는지 Metastore를 통해 확인 후에 Dag Run의 상태를 완료로 바꿈
- DagRun Status : Completed
⑻ Metastore가 Webserver에 업데이트해서 사용자도 확인
1.4 장점과 단점
1.4.1 장점
- 데이터 웨어하우스 구축, 머신러닝/분석/실험에 필요한 데이터 환경 구성에 유용함
- 데이터 파이프라인을 세밀하게 제어할 수 있음
- 다양한 데이터 소스, 데이터 웨어하우스, 데이터베이스 및 클라우드 서비스와의 통합이 가능함
- 파이썬 코드를 이용하여 복잡한 커스텀 파이프라인을 구현할 수 있으며, 다양한 시스템과의 통합이 용이함
- 정의된 특정 시점에 trigger할 수 있는 스케줄링 기능을 제공함
- 백필(Backfill)이 쉬움
1.4.2 단점
- 배우기가 쉽지 않고, 파이썬에 익숙하지 않은 사용자의 경우 DAG 구성이 어려울 수 있음
- 상대적으로 개발환경 구성이 어려움
- 작은 환경 변화에도 오류가 발생하기 쉬우며, 롤백이 필요한 경우가 종종 있음
- 직접적인 운영 및 관리가 어려워 클라우드 기반 서비스(예: Google Cloud의 Cloud Composer, AWS의 managed Workflows for Apache Airflow)의 사용이 선호됨
1.5 백필(Backfill)
Backfill은 데이터 파이프라인에서 과거 데이터를 처리하거나 재처리하는 과정입니다.
단어 그대로 ‘메우는 작업’으로, 쉽게 말하면 과거 데이터를 다시 채우는 과정으로 볼 수 있습니다.
이러한 Backfill은 파이프라인의 변경, 에러 수정, 누락된 데이터 처리 등의 상황에서 필수적입니다.
데이터 파이프라인이 수십개가 넘어가는 순간부터 관리가 어려워지고, 유지보수비용이 기하급수적으로 증가합니다.
더군다나, 데이터 파이프라인에는 문제가 생기기 쉬워 파이프라인을 체계적으로 관리해야 합니다.
이 때, Backfill을 쉽게 할 수 있는 이 기능만으로도 Airflow는 강력하다고 볼 수 있습니다.
** 이러한 이유 때문에, Backfill은 데이터 엔지니어들이 가지고 가야 할 숙제와 같음
Airflow를 사용하는 이유 중 하나가 Backfill인 만큼,
이 Backfill의 정확한 이해를 위해 Incremental Update와 Full Refresh에 대해서 먼저 알아보겠습니다.
1.5.1 Incremental Update
Incremental Update는데이터 저장소에 새로 추가된 데이터만을 업데이트하는 방식입니다.
이러한 Incremental Update는 유지보수가 어려울 수 있으며, 소스 데이터에 문제가 발생하거나 중복 데이터가
쌓일 경우 정기적인 데이터 정제가 필요합니다.
1.5.2 Full Refresh
Full Refresh는 매번 소스 데이터의 전체 내용을 읽어와 업데이트하는 방식입니다.
조금 더 이해가 쉽게 정리하자면, 매번 통째로 전체 테이블을 복사해서 테이블을 새로 만드는 방식입니다.
이러한 Full Refresh는 중복 데이터 문제에서 자유롭지만, 데이터 크기가 커질수록 비효율적일 수 있습니다.
특히, Incremental update환경에서 데이터가 중복이나 누락이 발생했을 때 Backfillng하는 것이 매우 중요합니다.
결론적으로, 멱등성(Idempotency)을 보장하는 것이 파이프라인 구축의 가장 중요한 문제입니다.
| 멱등성: 동일한 입력데이터로 파이프라인 여러번 실행해도 최종 테이블의 내용이 달라지지 않아야 한다는 것 ** 중복 데이터에 대한 통제를 통해 멱등성을 보장하는 방법이 있음 |
이를 달성하기 위해서는 '실패한 데이터 파이프라인을 재실행하는데 용이'하고, '과거 데이터를 채우는 과정이 간단'
해야 하는데, 이 때, Airflow는 DAG가 중간에 실패하였다면, 어떤 태스크에서 문제가 발생하였는지를 쉽게 대시보드
형태로 모니터링이 가능한 것과 같은 다양한 이점을 통해, 실패한 파이프라인의 재실행을 용이하게 만들어줍니다.
Airflow에서의 Backfill은 데이터 무결성을 유지하고, 파이프라인의 신뢰성을 강화하는 데 중요한 역할을 합니다.
그러나, 데이터의 크기와 Backfill의 범위에 따라 성능과 데이터소스(예: created_date)의 부하를 고려해야 합니다.
데이터가 작을 경우, 가능하면 Full Refresh 방식의 데이터 업데이트를 진행하지만,
만약 Incremental update만이 가능하다면 데이터의 생성, 수정, 삭제 시점을 기록하는 필드가 중요합니다.
Incremental update에서는 대상 데이터소스가 갖춰야할 필드의 조건이 있으며, 조건은 다음과 같습니다.
** 조건은 파이프라인 구축 이후 Incremental Update 상황에서 데이터의 변경을 효과적으로 추적하고 처리하기 위해
즉, Incremental Update을 수행하기 위해 데이터베이스 테이블이 아래와 같은 필드를 포함해야 한다는 것을 의미
| Created: 각 레코드가 처음 생성된 시점 - Incremental update에서 필수적이지는 않음 - 데이터의 수명 주기를 추적하거나 특정 시점 이후 생성된 레코드를 조회할 때 유용 |
| Modified: 각 레코드가 마지막에 수정된 시점 - 해당 필드가 있다면, 마지막 업데이트 이후 변경된 레코드만 선택하여 처리할 수 있음 - 해당 필드를 통해 데이터 처리의 효율성을 높이고 불필요한 작업을 수행하지 않을 수 있음 |
| Deleted: 레코드의 삭제 여부 - "Soft delete"라는 개념과 연관이 있는데, 이는 레코드를 데이터베이스에서 물리적으로 제거하는대신, 레코드를 "Deleted"라고 표시함으로서 삭제하는 방법을 의미 - 이를 통해 삭제된 레코드와 그렇지 않은 레코드를 구분할 수 있으며 필요에 따라 레코드를 복구할 수도 있게 됨 |
** 대상 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야 함
Airflow는 DAG가 배포되었을 때 자동으로 과거 시점부터 현재까지의 태스크를 실행할 수 있으며,
이를 통해 과거 데이터를 처리하거나 업데이트합니다.
또한, 특정 날짜 범위에 대해 수행될 수 있으며, 이는 DAG의 start_date와 end_date를 통해 설정됩니다.
이 때, DAG의 Catchup 파라미터가 True가 되어야 하고, start_date와 end_date를 적절히 설정해야 합니다.
여기서 Catchup 파라미터를 True 로 하면, start_date로부터 파이프라인이 실행되지 않은 모든 시간 대의
파이프라인을 재실행 하게 되지만, 대상 테이블이 Incremental update가 되는 경우에만 의미가 있습니다.
1.5.4 start_date
Airflow에서는 execution_date를 사용하여 각 Task Instance의 실행 시점을 관리합니다.
start_date가 DAG가 언제(어느 시점)부터 데이터를 처리하기 시작해야 하는지를 정의하는 날짜라면,
execution_date는 실제로 DAG가 데이터를 처리하는 기준 날짜입니다.
일반적으로 사용자가 execution_date를 직접 설정하지는 않고, Airflow의 스케줄러가 자동으로 이 값을
할당하여 DAG의 각 실행에 대한 타임스탬로 사용합니다.
DAG가 스케줄링되면, Airflow는 start_date를 기준으로 execution_date를 계산하여 각 작업(run)이 실행되어야
할 정확한 시점을 결정하며, 이는 Backfilling에 중요한 역할을 합니다.
이에 따라, 코드를 작성할 때 execution_date 파라미터를 통해 해당 작업이 처리해야 할 데이터의 날짜나 시간을
결정하도록 하여 작업이 예정된 시간에 실행되지 않았을 때도 과거 데이터를 올바르게 처리할 수 있도록 해야 합니다.
** 현재 시간을 기준으로 업데이트 대상을 선택하는 것은 안티 패턴
1.5.4 start_date
Incremental update에서 stard_date의 개념과 Catchup을 통해서 실수를 저지를 수 있으므로, 더 살펴보겠습니다.

매일 업데이트 되어야 하는 데이터일 때, 8일에는 7일까지의 데이터가 업데이트 되어야 합니다.
이 때, start_date는 작업을 시작하는 날짜가 아니라, 작업을 처리해야 할 데이터의 시작 날짜를 의미합니다.
DAG 실행 시, execution_date라는 타임스탬프를 할당하며, 이 날짜는 작업이 처리해야 할 데이터의 기준 날짜입니다.
즉, execution_date가 2020년 11월 7일이라면, 이 날짜를 기준으로 데이터를 처리하라는 의미입니다.
결론적으로, Airflow에서 데이터 처리 작업을 설정할 때, 실제로 작업이 시작되는 시간이 아니라 처리해야 할 데이터의
날짜를 start_date로 설정하면, 어떤 이유로 작업이 지연되어도 execution_date를 사용하여 올바른 데이터가 처리될
수 있도록 보장할 수 있습니다.
예를 들어, 만약 10일에 시스템이 가동되었고, 7일과 8일의 데이터를 업데이트해야 한다면,
각각의 날짜에 해당하는 execution_date를 가진 DAG를 실행하여 각 날짜의 데이터를 처리할 수 있습니다.
이렇게 execution_date를 기준으로 코드를 작성하면, 과거 날짜에 대한 backfill 작업이 더 쉬워지게 됩니다.

그러면 이번에는, 2020-08-10 02:00:00이 start_date로 설정된 daily job이 있습니다.
Catchup이 True로 설정되어 있고, 현재 시간이 2020-08-13 20:00:00이며, 처음으로 이 job이 활성화 되었다면,
이 경우에 이 job은 몇 번 실행될까요?
총 3번 실행됩니다.
start_date는 그 다음날 혹은 그 다음 시간 단위부터 작업을 수행하고,
Catchup이 True일 때는 start_date로 부터 실행되지 않은 모든 job을 실행하기 때문에 3번입니다.
잘 짚고 넘어가야할 점은, start_date는 DAG가 언제부터 데이터를 처리하기 시작해야 하는지를 정의하지만,
그러나 실제로는 start_date가 설정된 시간에서 작업이 시작하는 것이 아니라,
start_date로 지정된 시간의 다음 실행 주기에 첫 작업이 실행된다는 점입니다.
Airflow에서 Backfill에 대한 추가적인 내용은 다음과 같습니다.
- Backfill은 일별 혹은 시간별 업데이트를 의미함
- 마지막 업데이트 시간 기준 Backfill을 하는 경우, execution_data을 이용한 Backfill은 필요하지 않음
- 데이터의 크기가 커질수록 Backfill 기능을 구현해두는 것은 필수적임
- Airflow는 이 Backfill 작업을 굉장히 쉽게 만들지만, 데이터 소스의 도움 없이는 불가능함
- Full Refresh(전체 데이셋을 새로고침)를 한다면, Backfill은 필요하지 않음
- 단, 데이터 파이프라인의 변경으로 인해 과거 데이터를 다시 처리해야 하는 경우에는 필요할 수 있음
1.6 스케일링
① Scale-Up(스케일 업): 더 좋은 사양의 서버 사용, CPU 추가, 메모리 추가 등
** Udemy의 경우에도 거액 투자 전까지 서버 한 대로 버팀
② Scale-Out(스케일 아웃): 서버 추가
** 지금은 스케일링을 하는데 있어서 AWS 환경에서 직접 지원해주기 때문에,
금액을 지불하고 AWS의 자동 관리 시스템을 사용해도 좋음
1.7 고려사항
1.7.1 환경 설정
| [ airflow.cfg ] - 에어플로우의 환경설정 파일 - /var/lib/airflow/airflow.cfg 해당 경로에 위치 - 환경설정의 변경은 웹 서버 및 스케줄러를 다시 시작할 때 반영됨 - dag_dir_list_interval: dags_folder를 Airflow가 얼마나 자주 스캔하는지 명시(초 단위, default: 300) |
| [ DAGs 폴더] - [core] 섹션의 dags_folder가 반드시 DAG들이 있는 디렉토리가 되어야함 |
| [ Airflow Database ] - airflow의 메타데이터 데이터베이스는 기본적으로 sqlite를 사용 - 다만, 추후 확장을 위해 보통은 postgreSQL로 사용함 - 이 db는 주기적으로 백업 되어야 하며, 일정 수준이 되면 메타 db를 삭제하는 과정도 필요 (메타데이터의 크기가 굉장히 커질 때가 많아, 보통 s3로 백업하거나, aws rds를 사용할 경우 aws의 스냅샷(백업) 기능을 활용) |
| [ LocalExecutor ] - Executor는 airflow.cfg에서 설정할 수 있음 - Single Server를 사용할 경우, SequentialExecutor이나 LocalExecutor를 사용 - Cluster로 사용할 경우, SequentialExecutor, CeleryExecutor, KubernetesExecutor를 사용 |
| [ 암호 ] - airflow 2.0부터는 기본적으로 웹UI의 로그인을 기본적으로 설정함 - 이는 이전 해킹 관련 이슈 때문에 나온 것으로, 보통 실무에선 VPN 뒤쪽에 airflow의 웹UI를 놓고, Public 웹에선 들어오지 못하게 하는게 일반적임 - 이와 더불어, 강력한 암호를 사용하는 것도 필요함 |
1.7.2 로그 파일
Airflow의 로그 파일은 생각보다 눈덩이처럼 불어나는 경우가 많은데, 이 로그파일을 잘 관리해줘야 함
- 로그 파일의 경로는 /dev/airflow/logs
- 정기적으로 로그데이터를 정리해야 하며, 이를 위해 ShellOperator 기반으로 DAG를 작성하기도 함
1.7.3 Scale-Up
DAG가 많아지고, 서비스가 확장되면서 각 DAG의 환경이나 로그, 메타데이터가 다양해지고 커질 수 있습니다.
이를 관리하기 위해 Cloud Composer, MWAA, Azure의 Data Factory Managed Airflow를 사용할 수 있습니다.
클라우드 서비스를 활용하면 airflow 메타데이터 백업을 보다 쉽게 할 수도 있고,
Variables를 연결하여 백업할 수 있지만 비용문제가 따르게 됩니다.
이외에도, airflow의 상태를 점검할 수 있는 HealthCheckApi를 활용할 수도 있고,
devops팀과 연동해서 모니터링 툴에 airflow api를 연동할 수도 있습니다. (Data Dog, Grafana)
1.7.4 기타 주의사항
- Data Streaming Solution을 적용하기엔 적합하지 않음
- 초단위의(그 이하) 데이터 처리가 필요한 경우에 사용하기에는 부적절함
- 에어플로우는 반복적이거나 배치 태스크를 실행하는 기능에 초점이 맞춰져 있음
- Data Processing Framework (like Flink, Spark, Hadoop, etc ..)로 사용하는 것은 부적절함
- 데이터 프로세싱 작업에 최적화 되어있지않아서 매우 느림
- 경우에 따라 메모리 부족으로 작업이 진행되지 않을 수도 있음
⇒ SparkSubmitOperator와 같은 Operator를 이용하여, 프로세싱은 Spark와 같은 외부 Framework로 처리
- 파이프라인의 규모가 커지면 파이썬 코드가 굉장히 복잡해질 수 있으므로, 초기 사용 시점에 엄격한 관리를 해야함
방향 비순환 그래프(Directed Acyclic Graph, DAG)
1. DAG
DAG는 단어 뜻 그대로 방향성을 가진 순환하지 않는 그래프입니다.
즉, 노드와 노드가 단방향으로 연결되어 있어 그 노드로 향하게 되면 돌아오지 않는 특성을 가지고 있습니다.
Airflow에서는 하나의 DAG가 하나의 완전한 workflow를 나타내며, DAG를 이용해 workflow를 구성하여 어떤 순서로
task를 실행시킬 것인지, dependency를 어떻게 표현할 것인지 등을 설정합니다.

각 DAG는 여러 개의 task와 task들 간의 종속성을 포함합니다.
이러한 task들은 일정한 순서에 따라(=순차적으로) 실행되며, 각 task는 작업의 한 단계를 나타냅니다.
이 때 중요한 점은 순환 실행을 방지한다는 점으로, 논리적 오류는 교착상태(dead lock)로 이어지게 됩니다.
DAG는 Task로 구성되고, Task는 Airflow의 Operator로 만들어집니다.
다르게 말하면, Operator는 DAG 내의 Task를 나타내고, 각 Task는 workflow의 한 단계를 구현합니다.
Airflow에서는 이미 다양한 종류의 Operator를 제공하고, 경우에 맞게 Operator를 결정하거나 개발합니다.
1.1 Operator
Operator는 workflow(DAG) 내에서 개별적인 작업을 정의하는 구성 요소로, 특정 Task의 작업 내용(예: 데이터를 다른
시스템으로 전송하거나 데이터베이스에서 쿼리를 실행하는 작업 등) 을 정의합니다.
1.1.1 유형
① Action Operators: 기능이나 명령을 실행하는 operator로, 실제 연산 및 데이터 추출 및 프로세싱을 수행
② Transfer Operators: 하나의 시스템을 다른 시스템으로 전송(예: 데이터를 Presto에서 MySQL로 전송)
③ Sensor Operators: 조건(예: 외부 시스템의 작업 완료)이 만족할 때까지 기다렸다가, 충족되면 다음 Task를 실행
| [ 종류 예시 ] - Python Operator: 파이썬 함수를 실행 - Bash Operator: 배쉬 스크립트를 실행 - S3ToRedshift Operator: 아마존S3에서 Redshift로 데이터를 전송 |
| [ 사용 예시 ] - Sql Operator: DB에서 데이터를 추출 - Python Operator: 데이터를 변환하거나 분석 - Email Operator: 결과를 이메일로 전송 - S3ToRedshift Operator: 데이터 웨어하우스에 데이터를 적재 |
1.2 Task & Task Instance
위에서 설명드린 것처럼, Task는 데이터 파이프라인에 존재하는 Operator를 의미합니다.
Operator를 실행하면 Task가 되고, 파이프라인이 Trigger되어 실행될 때 생성된 Task를 Task Instance라고 합니다.
Task는 작업의 정의를, Task Instance는 그 작업이 실제로 실행될 때의 구체적인 경우(Instance)를 의미합니다.
데이터 파이프라인이 실행될 때 마다, 각 Task에 대해 새로운 Task Instance가 생성되며,
이 Instance는 Task의 실행 상태(예: 대기 중, 실행 중, 성공, 실패 등)와 같은 정보를 포함합니다.
추가적으로, Airflow에서 Task 간의 의존성은 파이썬 연산자를 사용하여 정의됩니다.
예를 들어, 오른쪽 시프트 연산자(binary right shift operator, >>)를 사용해 Task간의 순서 및 의존성을 정의합니다.
- t1 >> [t2,t3] : t1 태스크를 진행 후에, t2, t3를 동시에 진행시켜라
- t1 >> t2 >> t3 : t1 태스크 후에, t2 태스크를 진행하고, t3 태스크를 진행시켜라
이러한 방식으로, Airflow는 Task간의 복잡한 의존성과 실행 순서를 쉽고 직관적으로 정의할 수 있게 해줍니다.
1.3 Operator vs. Task
사용자 관점에서는 두 용어를 같은 의미로 볼 수 있지만, Task는 작업의 올바른 실행을 보장하기 위한 매니저입니다.
쉽게 말해, Operator는 '어떤 작업을 할 것인가'를 정의하고, Task는 '실제로 작업을 수행하는 인스턴스'입니다.
즉, 사용자는 Operator를 정의하고 구성하는데 집중하며, Airflow는 이러한 정의에 따라 Task를 실행하고 관리합니다.
참고 자료
Apache Airflow 기반의 데이터 파이프라인 - 바스 하렌슬락, 율리안 더라위터르 - 제이펍
https://lsjsj92.tistory.com/631
댓글